Back in 2010 we were helping Parship to migrate their platform to a new provider and establish working application management. Migration to a new hosting provider and parallel re-architecturing of the platform is a funny combination and it actually rattled from time to time. Now imagine the situation were you have 4 different parties with at least 4 different tools and every tool shows something different.
The ‘new’ provider had it op5 and its monitoring system, the internal Ops guys had their Munins, the management was all about Omniture and pixel tracking and finally, the developers had MoSKito. Also MoSKito credible showed the outages, we had funny discussion about the system states between the different parties. An example conversation would go like this:
Management: we have not enough registrations in omniture.
Developers: yes, we see that the foobarservice is overloaded, we probably have some problems in the environment.
Hosting provider: but on my monitoring the cpu and disk are ok!
Basically we spent more time arguing about system state as actually repairing it. And it was very expensive time, because the customers experienced real problems out there. Finally we proposed the Project 36 Lamps.
The idea was to identify critical components and to have one page on which a lamp for every component is burning. If the lamp is green, everything is ok, but if it’s not, we all know that the state of a component has to be investigated. The following picture explains the idea:
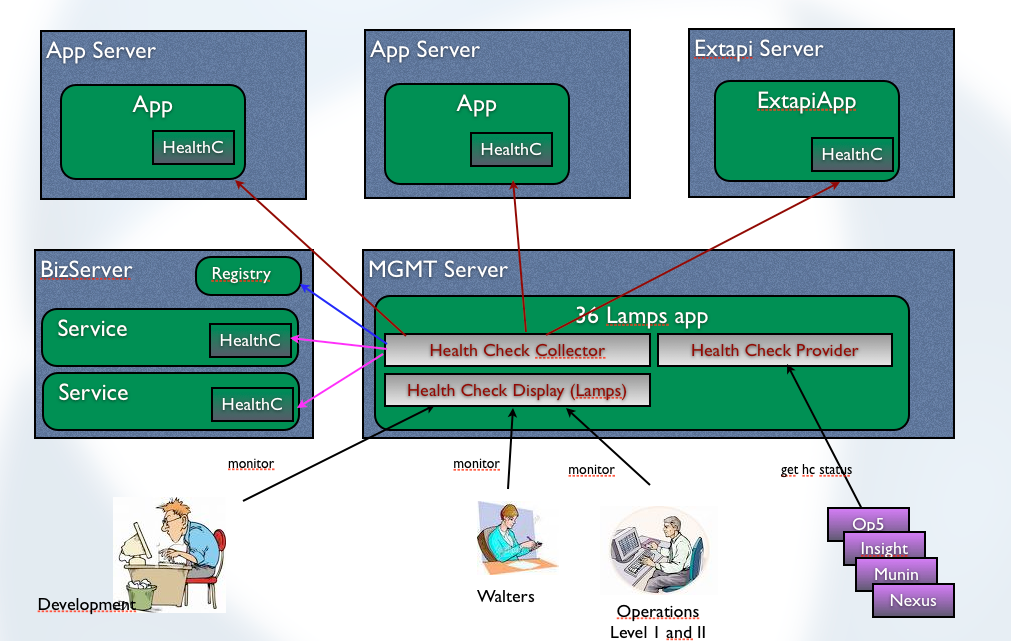
During wireframe creation process we renamed the project from 36 Lamps to Central Healthcheck Monitor and the abbreviation CHMO which sounds funny in russian (but you’ll have to search for translation yourself). However, this is how it should look like:
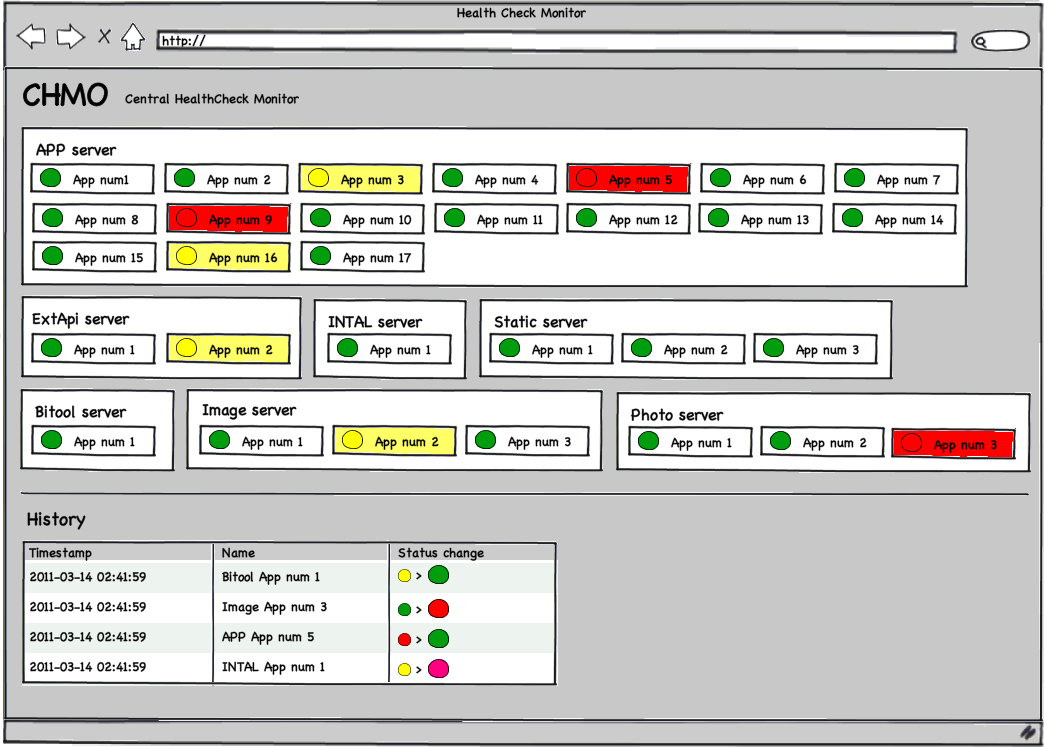
And what the designer made of it:
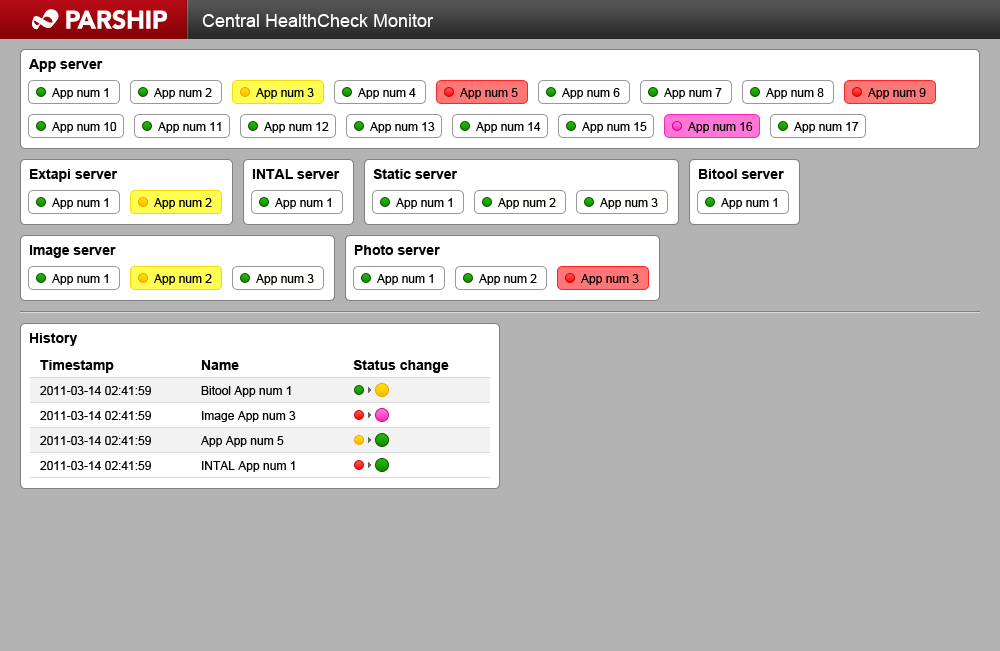
Couple of month later the new HealthCheckMonitor went live and everyone was more or less happy with it (or had to be happy with it) and the above display happily occupied a big tv screen in both developers and ops rooms. From now on a regular glance at the tv screen with the healthcheck monitor was a common habit among both, devs and ops. It was and is also the first things to consult in case of any reported problems. Mission accomplished.
2 years later in 2012 we actually asked Parship if they are willing to donate their custom developed tool back to the open source project. And, thanks for that Parship!, they agreed 🙂 Of course we took the possibility to review the code at current state and took the opportunity to change a thing or two. Or maybe rather 3 or 4. And our new designer has adopted the look & feel to other new MoSKito tools, like our new iPad app. And that’s what came out:
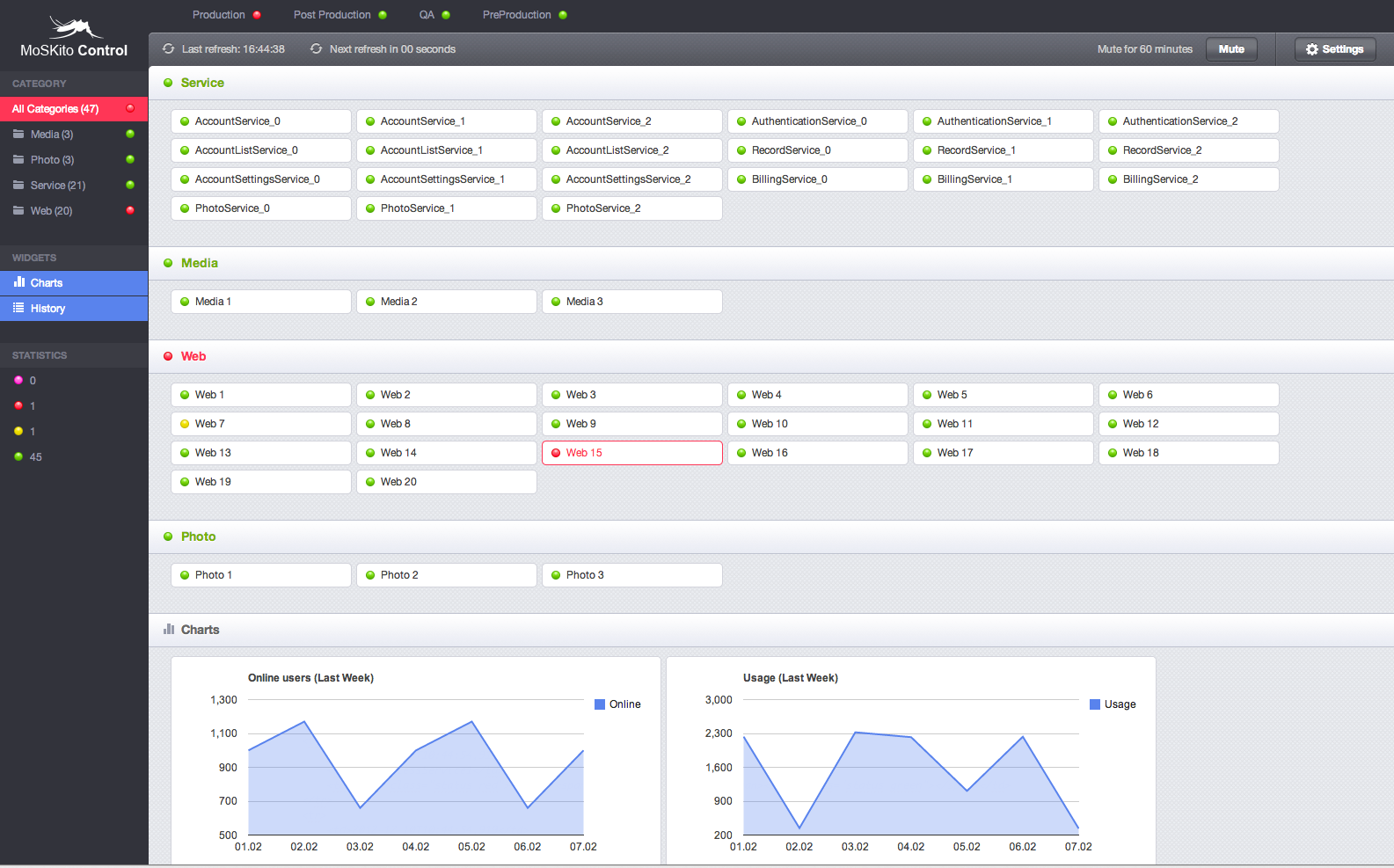
Pretty cute isn’t it 😉 So what’s the deal, how it works and what’s your gain.
MoSKito-Control supports multiple applications, with multiple components each. The applications can be truly different applications or different staging states of same application, it’s up to you. Each component of an application is either a separate running Java VM or at least has its own state. MoSKito-Control provides a set of agents that can be deployed into the application and offers the application state to be picked up. The state is determined by the status of MoSKito Thresholds.
So you basically need a moskito-core and an agent into each of your components and you have it all setup and running. We strongly recommend to access the components and applications by the same way, they are using to access each other. This means that moskito control should access a web server via http request and an ejb container via remote ejb. Otherwise you can have a non reachable component shown as green in monitoring. And that’s the last thing you want to have.
MoSKito-Control is currently being further inspected and adopted and scheduled for second half of Mai.
MoSKito-Control is placed on GitHub:
You can click the mock if you can’t expect it 😉
http://server04.test.anotheria.net:8080/moskito-control/control/main
So… try, enjoy, participate.
Leon